




Представьте цифровой каталог, где каждый товар идеально описан нужными характеристиками, поиск происходит за доли секунды, а добавление новых свойств не требует постоянного привлечения разработчиков. Структура данных в Pimcore — это не техническая мелочь, а важнейший инструмент, который влияет на бизнес-результаты:
✅ Эффективность команды – интуитивная панель управления ускоряет работу контент-менеджеров в 2-3 раза.
✅ Рост продаж – правильные фильтры и атрибуты повышают конверсию на 15-25%.
✅ Экономия бюджета – продуманная архитектура снижает затраты на поддержку на 30-50%.
Ошибки при выборе структуры данных приводят к административному хаосу, медленному интерфейсу и техническому долгу, которые замедляют развитие бизнеса.
В статье рассмотрим три основных подхода к организации атрибутов в Pimcore:
- FieldCollection
- ObjectBricks
- Classification Store
Подробно разберём их возможности, преимущества и ограничения, чтобы вы могли выбрать оптимальный вариант.
FieldCollection – идеальный инструмент для повторяющихся свойств
Для чего подходит: FieldCollection подходит для работы с товарами, у которых есть типовые, повторяющиеся характеристики. Например, в мебельном интернет-магазине шкафы, кровати и столы описываются стандартными атрибутами: цвет, размер, материал, при этом значения этих атрибутов могут различаться.
Суть технологии
FieldCollection — это строго типизированные наборы полей, многократно используемые в разных объектах. Каждый набор хранится в отдельной таблице базы данных, обеспечивая высокую скорость работы.

Преимущества FieldCollection:
- Определение полей один раз
- Интуитивно понятный интерфейс
- Стабильная производительность БД
- Эффективное кэширование
- Универсальность для интеграций
- Многократное использование созданных наборов свойств
- Группировка полей по смыслу
- Добавление новых свойств без разработчиков
- Поддержка ссылок на другие объекты
Ограничения FieldCollection:
- Не подходит для динамически изменяемых атрибутов
- Новое свойство автоматически применяется ко всем связанным объектам
- Ограниченная масштабируемость при очень больших каталогах (свыше 100 000 SKU)
- Неудобство при массовой корректировке данных
- Отсутствие гибкого управления доступом
Экспертная рекомендация:
Используйте FieldCollection, когда вам нужны предсказуемые, повторяющиеся структуры данных с минимальными изменениями в будущем.
ObjectBricks – уникальные характеристики для каждой категории
Для чего подходит: ObjectBricks подходит для случаев, когда каждая категория товаров требует собственного набора характеристик — например, в каталоге электроники: у смартфонов это «диагональ экрана» и «ОС», а у ноутбуков — «процессор» и «видеокарта».
Суть технологии
ObjectBricks позволяет создавать и подключать уникальные наборы атрибутов к объектам в зависимости от категорий и условий.

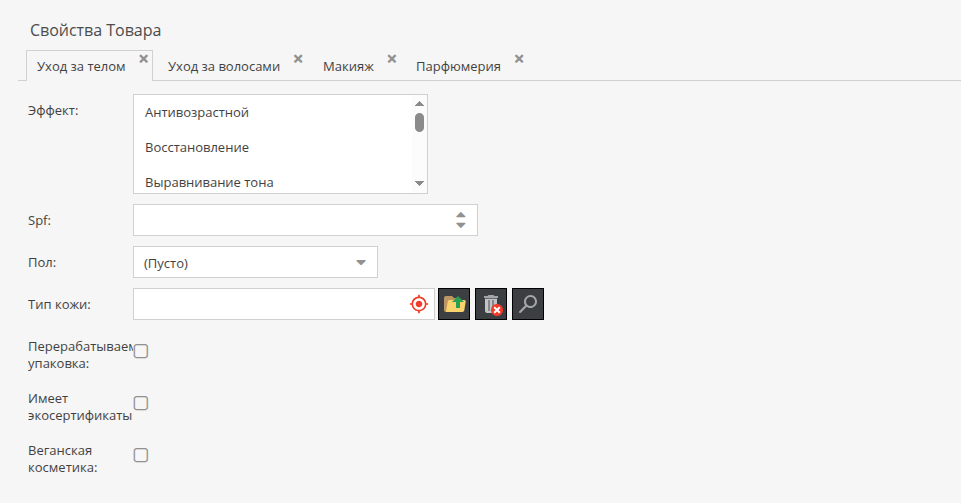
Преимущества ObjectBricks:
- Индивидуальные наборы полей для каждой категории
- Многократное использование созданных наборов атрибутов
- Гибкое разграничение прав доступа
- Стабильная производительность при работе с БД
- Автоматическая поддержка интеграций
- Поддержка мультиязычности на уровне поля
- Наследование атрибутов от мастер-карточек
Ограничения ObjectBricks:
- Нет вложенности блоков (только один уровень).
- При большом количестве категорий и блоков возникает сложность управления.
- Повторяющиеся свойства в разных блоках требуют дублирования и дополнительной поддержки.
Экспертная рекомендация: Используйте ObjectBricks, если у вас стабильные категории с чётко выделенными уникальными атрибутами и умеренным числом категорий.
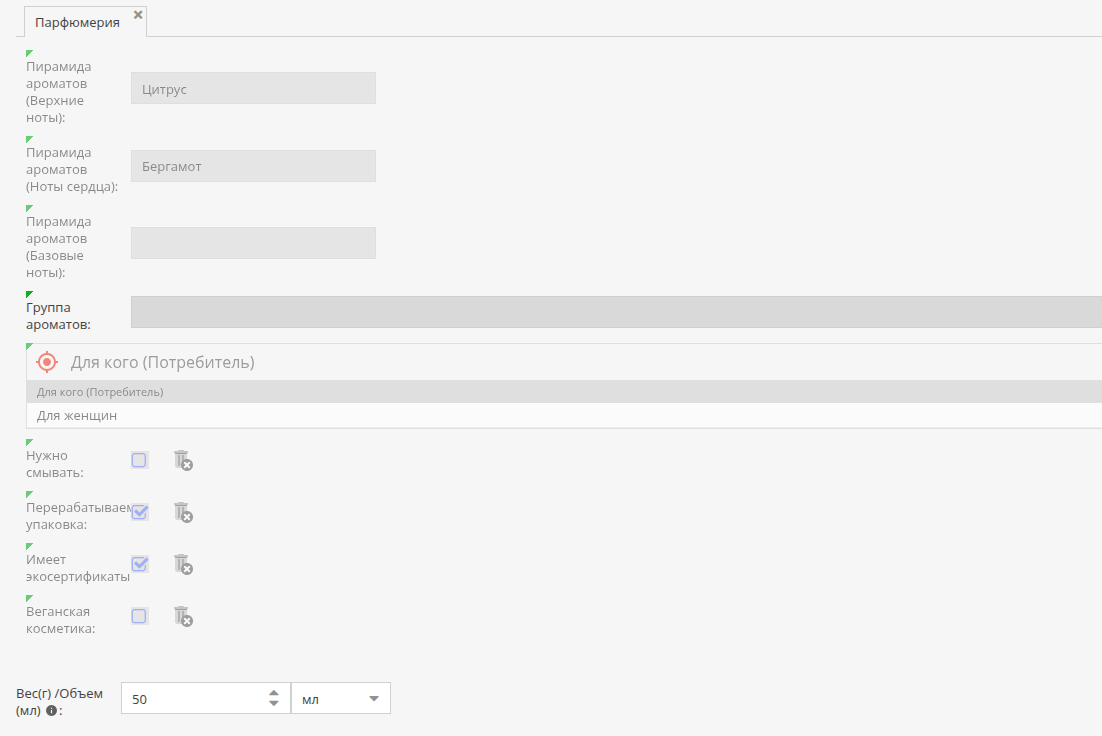
Classification Store – повторяй, группируй, управляй: всё в одном месте
Для чего подходит: Classification Store подходит для динамичных каталогов, где характеристики часто меняются — например, на маркетплейсе с товарами от множества поставщиков, где свойства регулярно добавляются и удаляются.
Classification Store подходит для гибкого, централизованного управления динамическими атрибутами в больших и изменчивых каталогах.
Суть технологии
Classification Store — централизованное хранилище атрибутов, которые динамически привязываются к объектам и могут использоваться многократно.


Преимущества Classification Store:
- Централизованное управление атрибутами по всему каталогу.
- Создания и удаления атрибутов без изменения структуры базы данных.
- Максимальная гибкость для динамически меняющихся каталогов.
- Повторное использование атрибутов в разных классах товаров.
- Поддержка мультиязычности.
- Возможность задавать порядок отображения и обязательность заполнения атрибутов в разрезе конкретных категорий.
- Структурированная организация: атрибуты можно объединять в группы, а группы — в коллекции, что упрощает навигацию и управление.
Ограничения Classification Store:
- Первоначальная настройка требует изучения технологии.
- Ограниченный набор типов данных (нет связей с другими объектами).
- Высокая сложность администрирования при большом количестве атрибутов.
- Нет гибкого управления доступом: права назначаются на весь Classification Store, а не на отдельные поля.
Экспертная рекомендация: Выбирайте Classification Store для крупных и динамичных каталогов, где критично быстро адаптироваться к изменениям.
Чек-лист: какой инструмент лучше выбрать?
Для удобства выбора воспользуйтесь подробной сравнительной таблицей с ключевыми критериями и понятными обозначениями:
Легенда:
✅ — высокая степень соответствия
⚠ — средняя степень соответствия
❌ — низкая степень соответствия
Подробная сравнительная таблица:

Как выбрать оптимальный инструмент: коротко о главном
Чтобы выбрать идеальную структуру данных, задайте себе три ключевых вопроса:
Как часто меняются атрибуты моего каталога?
Редко — FieldCollection.
Часто — Classification Store или ObjectBricks.
Насколько важна производительность и простота?
Максимум скорости — FieldCollection.
Баланс — ObjectBricks.
Гибкость важнее скорости — Classification Store.
Какой уровень вложений в сопровождение системы для вас комфортен?
Минимум ресурсов — FieldCollection.
Умеренные затраты — ObjectBricks.
Готовы инвестировать в гибкость — Classification Store.
💡 И главное — эти инструменты не взаимоисключающие.
В рамках одного проекта можно комбинировать подходы: использовать FieldCollection для стабильных блоков, ObjectBricks для уникальных категорий и Classification Store для часто меняющихся параметров. Такая комбинация позволяет создать архитектуру, максимально соответствующую бизнес-модели, масштабам и бюджету компании.
Не уверены в выборе? Наши эксперты помогут вам провести аудит текущей системы и подберут оптимальное решение.
Главный секрет успеха — это не самая сложная структура данных, а та, что идеально соответствует вашим задачам, бюджету и стратегии роста.
Сделайте правильный выбор и превратите управление атрибутами в конкурентное преимущество!



